
GPU Fleet — Overview
GPU Fleet, kendi GPU makinelerini console üzerinden uçtan uca yönetmeni sağlar:
- Linux + NVIDIA, macOS + Apple Silicon ve CPU-only makineleri tek arayüzden onboard et.
- Curated bir model kataloğundan (Qwen, Llama, Mistral, BGE embeddings, Whisper, XTTS, EasyOCR…) tıkla-deploy yap.
- Aynı modeli N makinede çalıştırıp tek bir OpenAI-compatible endpoint arkasına koy (Pool).
- A100/H100 üzerinde MIG ile fiziksel GPU'yu mantıksal parçalara böl.
- Her host'ta UI'dan terminal aç (host shell / sandbox / container exec).
- Health, agent durumu, deployment durumu — hepsi tek pane'de.
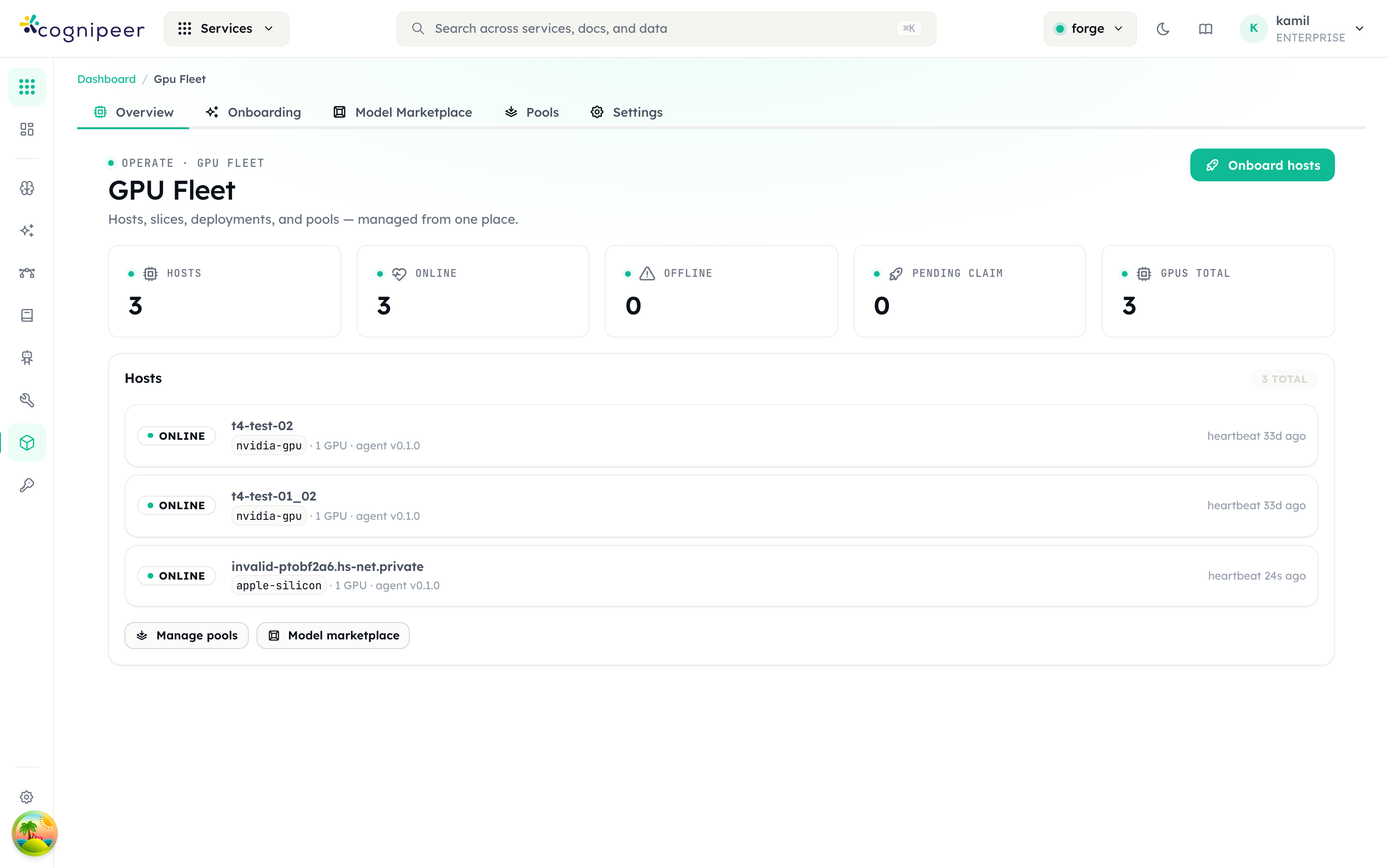
Operate → GPU Fleet altında; üst sekmeler Overview / Onboarding / Model Marketplace / Pools / Settings. Overview, host/online/offline/pending-claim ve toplam GPU sayaçlarını, her host için durum + heartbeat + agent sürümü kartını gösterir. Onboard hosts yeni makine ekler.
Mimari özet
┌──────────────────────┐ long-poll ┌──────────────────────┐
│ Cognipeer │ ◀──── handshake ──────────── │ gpu-agent (Node) │
│ Console │ heartbeat, events │ - platform adapter │
│ (multi-tenant API) │ ─────────────────────────────▶│ - docker (vllm/…) │
│ │ desired-state commands │ - mig (nvidia-smi) │
│ + UI │ │ - terminal pty │
│ + Pool proxy │ ◀───── /api/internal/ │ │
│ + DB │ gpu-pool/.../v1 │ │
└──────────────────────┘ └──────────────────────┘
GPU host- Agent her makineye kurulur, console'a outbound bağlanır (firewall dostu).
- Console desired-state'i DB'de tutar, agent farkı uygular.
- Pool proxy birden çok deployment'ı tek OpenAI uyumlu endpoint arkasında load-balance eder.
Hızlı başlangıç
- GPU Fleet → Settings sekmesinden bir fleet token üret (Rotate fleet token).
- Onboarding sekmesinden bilgisayarına özel install command'ı kopyala.
- Her GPU host'unda komutu çalıştır → host pending claim olarak görünür.
- UI'dan host'u claim et (ad ver, terminal'i opt-in olarak aç).
- Model Marketplace'ten model seç, host detayında Deploy model → birkaç dakika sonra healthy.
- Birden çok host'a aynı modeli kurmak istersen Pools → Bulk deploy.
Detay için sıradaki rehberlere bak.
Roller ve izinler
GPU Fleet, gpu-fleet servis izniyle korunur (admin-only). RBAC tarafında bu izni verirken admin seviyesi gerekir; daha düşük seviyeler şu an desteklenmez (alt seviye okuma desteği planlı).
Terminal erişimi ayrıca host bazında opt-in (terminalEnabled) — claim sırasında veya sonra UI'dan aç/kapa. Bu, RBAC izniyle birlikte iki-faktörlü çalışır: izin AND flag açık olmadan terminal açılmaz.
Veri modeli (özet)
| Entity | Açıklama |
|---|---|
gpu_hosts | Console'a bağlı GPU/CPU makineleri. Status: pending_claim → online → offline. |
gpu_slices | Schedule edilebilir parça: full-GPU veya MIG instance. Bir deployment'a bağlanır. |
llm_deployments | Slice üzerinde koşan Docker container (vLLM / TGI / Ollama / custom). |
gpu_fleet_commands | Konsoldan agent'a giden komut kuyruğu (FIFO, idempotent). |
gpu_fleet_events | Append-only event log (audit + state propagation). |
gpu_fleet_settings | Tenant-wide ayarlar (fleet token, agent distribution mode, terminal TTL). |
llm_pools | Aynı modeli çalıştıran deployment'ları gruplayan load-balanced endpoint. |
Lifecycle
Host: [register] → pending_claim ──claim──▶ online ◀──heartbeat── (offline if stale)
Deployment: pending → pulling → starting → healthy ◀──── unhealthy / failed / stopped
Pool: active ──drain──▶ disabled (delete tamamen siler)
Slice: agent reports → console upserts → MIG reconfig deletes/recreatesSonraki adım
→ Onboarding Hosts — ilk makineyi bağla.